Data Flow
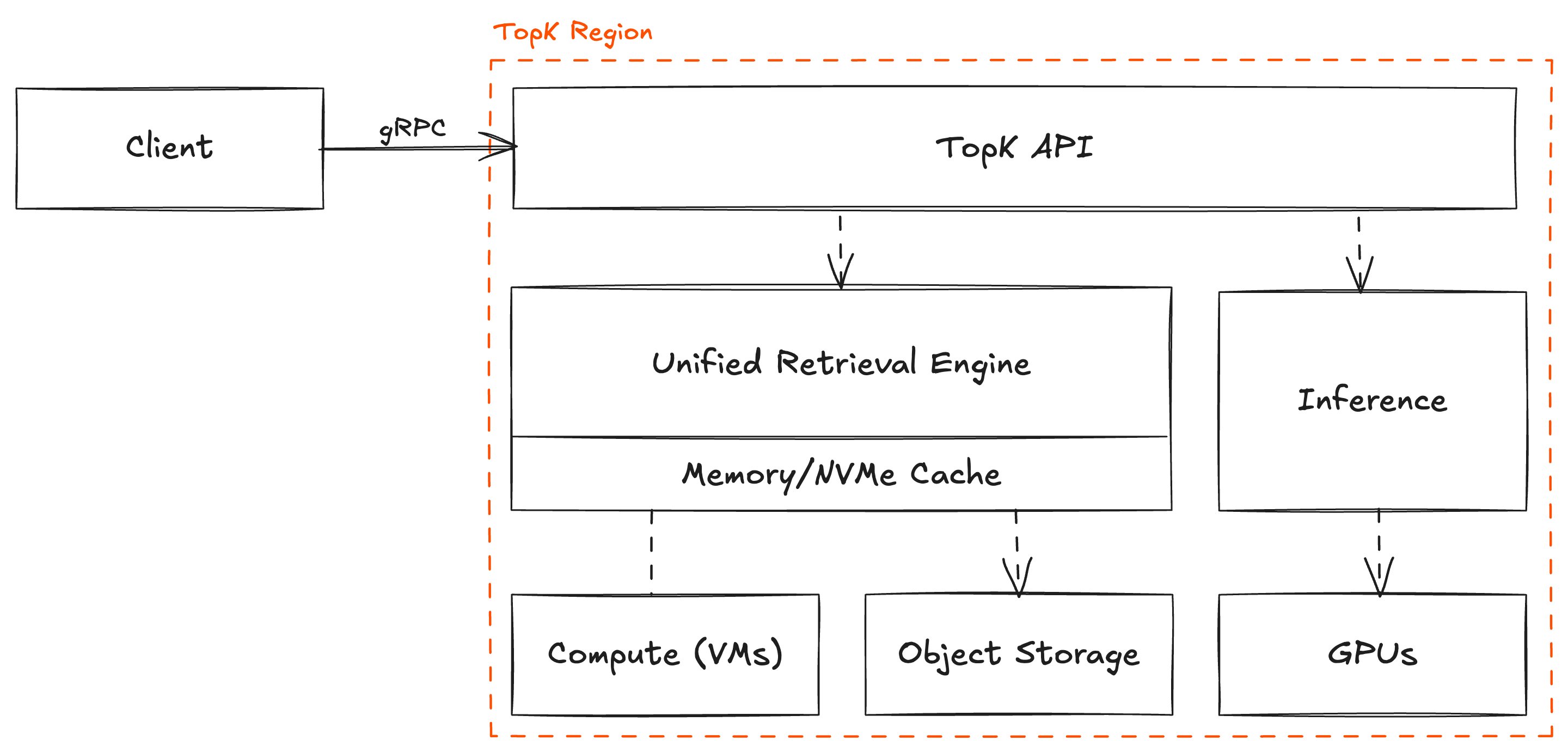
TopK is a multi-tenant service, which means that each tenant shares the same physical infrastructure with other tenants in the same region. This allows us to offer lower costs and better burst capacity. For enterprise customers that require full isolation and data residency, we offer dedicated single-tenant regions or cloud-prem deployments in customer-managed VPC.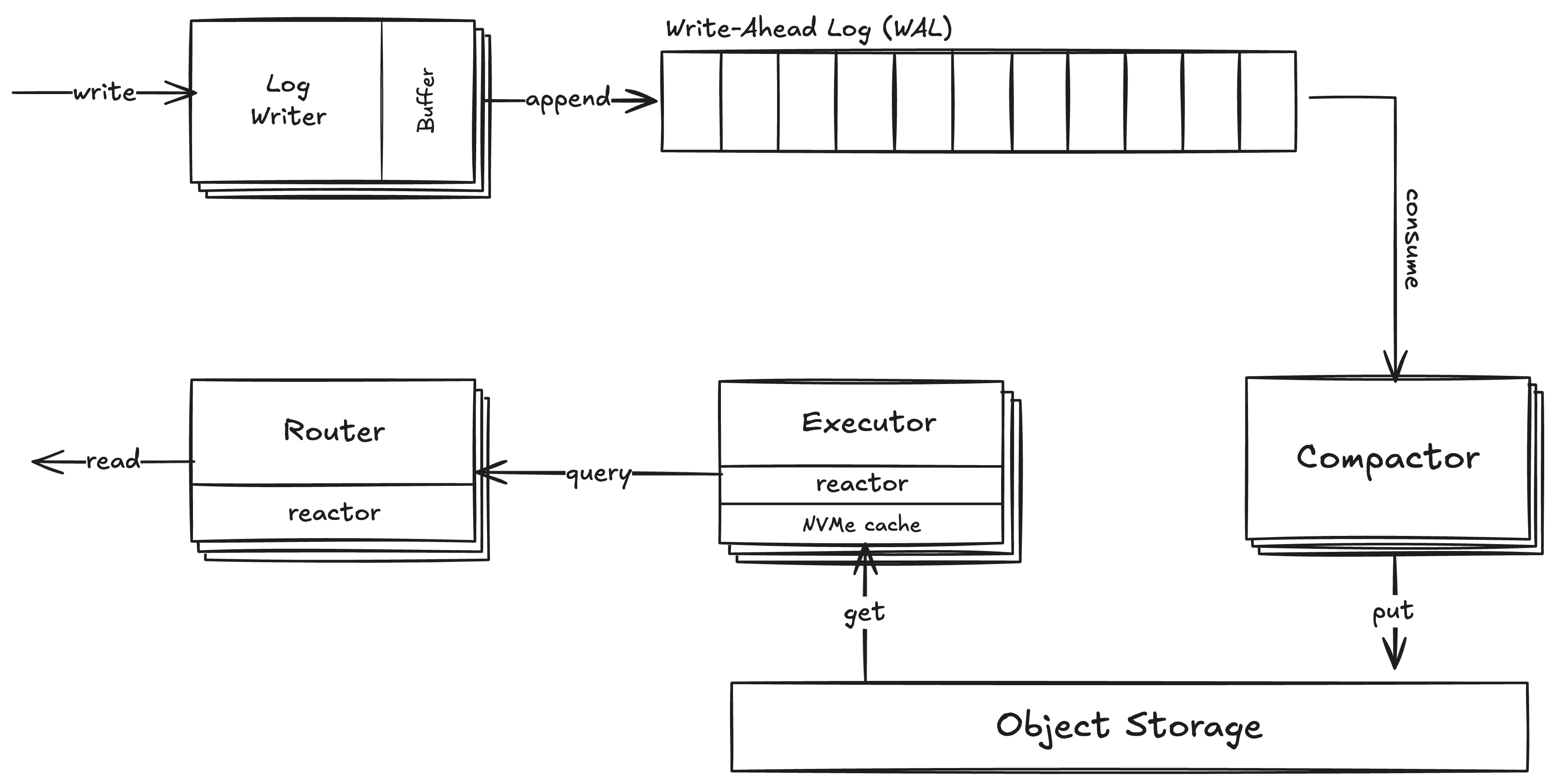
Write Path
Write-Ahead Log (WAL)
Write requests are durably persisted in a write-ahead log (WAL) which is backed by object storage. Entries in the WAL use logical log sequence numbers (LSN) to guarantee strict ordering and serializability. Once a write request returns successfully, data is guaranteed to be durably persisted to object storage. We employ dynamic batching to improve write throughput (~70MB/s or ~30,000+ vectors/sec) at the cost of higher write latency (~300ms p99 <1MB).Compactor (LSM-tree)
The write-ahead log is an append-only data structure with an unbounded number of entries. To optimize query performance and reduce storage costs, we periodically flush new WAL entries into more read-optimized format. The read-optimized files are stored as sorted runs inside a log-structured merge tree (LSM-tree). This tree is then periodically compacted to minimize read amplification, remove updated or deleted data, and minimize storage space. Since all data is persisted on object storage with massive I/O throughput, we developed a scalable compaction planner and executor that allows us to flush new WAL entries and merge existing segments in parallel on a distributed set of nodes.Read Path
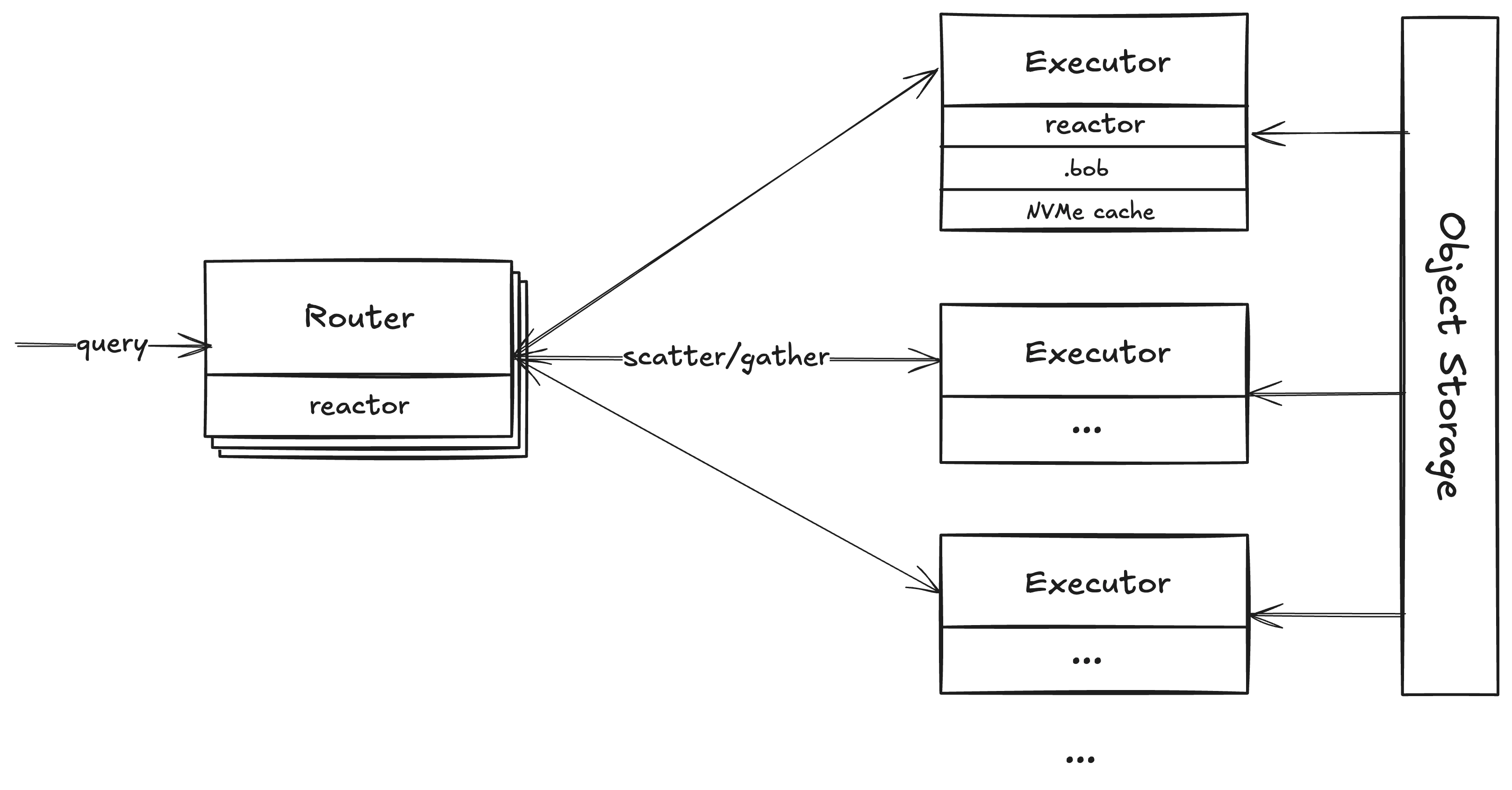
Router
The router service is the front door for all read requests. It handles validation, query planning and optimization, consistent routing to optimize cache hit rates, and acts as a coordinator for distributed query execution. This decoupling allows us to horizontally scale compute resources and serve billion-scale collections with low latency and high throughput.Executor
The executor service has two primary responsibilities: (1) executing (partial) query plans computed by the router and (2) caching data in memory and on NVMe SSDs. Every executor node is semi-ephemeral and fungible. In practice, this means that the persistent on-disk cache state survives restarts and deployments to minimize disruptions during rollouts. At the same time, we can lose an executor node without losing data or availability since the router will automatically redistribute requests to other executor nodes that will pull the required data from object storage.Cache Hierarchy
Our query engine and storage format are designed from the ground up for multi-tier cache hierarchy. All data is persisted on object storage which is our primary/only durable storage. Executor nodes then cache a subset of this data required for query execution in memory and on locally attached NVMe SSDs to minimize latency and maximize throughput. Cache placement and I/O requests are handled by our I/O runtime (based onio_uring) optimized to efficiently utilize the massive read throughput of object storage and NVMe SSDs.
Query Engine (reactor)

reactor is our proprietary query engine that enables us to combine different retrieval types, filter predicates, and scoring expressions in a single query. Conceptually, it’s similar to other pull-based query engines (e.g. DataFusion) with heavy optimizations for zero-copy execution, search-specific SIMD kernels, quantization, vectorized filtering, pruning, and more. Additionally, it supports distributed query executions which allows us to reuse the same logical/physical operators in router and executor services.
File Format (.bob)
.bob is our proprietary columnar file format designed from the ground up for search on object storage. It supports zero-copy and zero-decode I/O with type-specific containers for compressed dense and sparse vectors, tensors, inverted indices, and more.
CMU DB: TopK Talk
Check out our talk at the Carnegie Mellon University Database Group where we dive deeper into the TopK architecture,reactor, .bob, and more.